
Recently, our robotics team published a paper in IJCV 2022 titled “Scene Reconstruction with Functional Objects for Robot Autonomy.” They introduced an innovative problem of scene reconstruction and representation, offering essential information for robotic autonomy while enabling interactive virtual scenes that closely mimic real-world scenarios for simulation testing. Furthermore, this research developed a comprehensive machine vision system to tackle the proposed scene reconstruction issue. The experiments showcased the effectiveness of the suggested scene reconstruction approach and the potential of scene representation for robot autonomy planning.
Perceiving the three-dimensional environment and understanding the information it contains is a crucial aspect of human intelligence and a prerequisite for interactive engagement with the environment. Beyond the geometric features of the environment and the semantic information of objects, we can also “perceive” the potential ways of interacting with the environment, which we refer to as actionable information. For example, when we see a doorknob as shown in Figure 1(a), we naturally imagine the potential action of turning the doorknob and opening the door. In the scene depicted in Figure 1(b), we can easily observe the constraint relationship (mutual support) between stacked cups and dishes, as well as the effects of different actions on their states (directly extracting the bottom cups and dishes would cause the top ones to topple, while removing the top objects one by one allows us to safely retrieve the bottom cups and dishes). Understanding the impact of potential actions on a scene forms the basis for performing tasks and interacting within that scene. Similarly, intelligent robots require similar perceptual capabilities to autonomously accomplish complex long-horizon planning in their environment.


Fig. 1 (a) Door handle, (b) Stacked cups and dishes (Image source: Internet, copyright belongs to the original author)
With the development of 3D scene reconstruction and semantic mapping technologies, robots are now capable of efficiently building three-dimensional maps that incorporate both geometric and semantic information. For instance, they can create semantic panoptic maps that encompass object and room structure information, as shown in Figure 2(b). However, there still exists a significant gap between these traditional scene representations derived from scene reconstruction and the realization of autonomous robot planning. The question then arises: How can we construct a scene representation that is universally applicable to robot perception and planning to enhance the robot’s autonomous planning capabilities? How can robots leverage their own sensor inputs, such as RGB-D cameras, to construct such a scene representation in real-world environments?
In this paper [1], researchers address this challenge by proposing a novel research problem: the reconstruction of functionally-equivalent and interactive virtual scenes that preserve the actionable information from the original scenes. These reconstructed virtual scenes can be used for simulated training and testing of robot autonomous planning. To achieve this reconstruction task, the researchers introduce a scene graph representation based on supporting and proximal relations, as depicted in Figure 2(a). Each node in this scene graph represents an object or a room structure (e.g., walls, floor, roof) in the scene. This scene graph representation organizes the reconstructed scene and its physical constraints to ensure that the resulting virtual scene adheres to physical common sense. Moreover, it can be directly converted into an environment’s kinematic tree, which comprehensively describes the kinematic relationship states of the environment and supports forward prediction of the effects of robot actions on the environment. This representation can be directly utilized in robot planning tasks. The paper also presents a complete machine vision system to realize this reconstruction task and designs output interfaces for the reconstructed scene, enabling seamless integration with robot simulators (e.g., Gazebo) and virtual reality environments. Some preliminary work of this paper [2] was previously published at ICRA 2021.
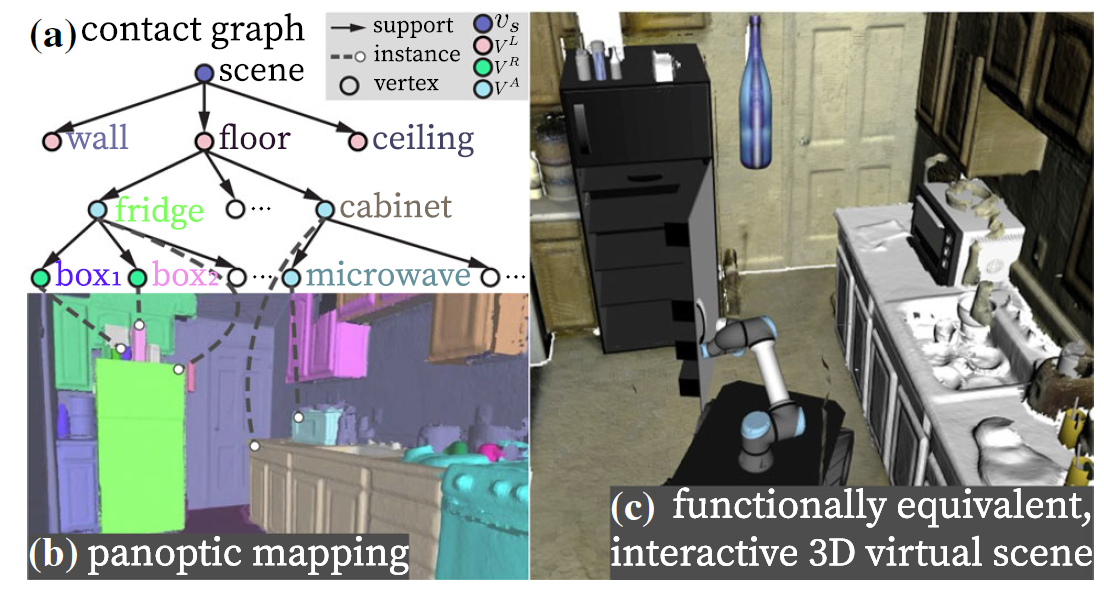
Fig. 2 (a) Scene graph based on supporting and proximal relations, (b) Volumetric semantic panorama, (c) Functionally-equivalent and interactive virtual scene that replicates real-world functionality for simulation testing in robot autonomous planning
Reconstructing real scenes in virtual environments to support robot simulation is not a straightforward task. There are three main challenges: First, accurately reconstructing and segmenting the geometry of each object and structure in cluttered real scenes and estimating the physical constraints between objects (e.g., supporting relationships). Second, replacing the reconstructed incomplete geometry with complete and interactive objects (e.g., CAD models). Third, integrating all this information into a unified scene representation that assists both scene reconstruction and robot autonomous planning.
This work proposes the use of a specialized scene graph as a bridge between scene reconstruction and robot interaction, providing necessary information for both reconstructing physically plausible virtual scenes and enabling robot autonomous planning. On one hand, this scene graph organizes the perceived objects, room structures, and their relationships in the scene, as shown in Figure 3(a). Each node in the scene graph represents an identified and reconstructed object or room structure in the real scene, including its geometry (e.g., reconstructed 3D mesh, 3D bounding boxes, extracted plane features) and semantic information (such as instance and semantic labels). Each edge represents either a supporting relationship (directed edge in Figure 3(a)) or a proximal relationship (undirected edge in Figure 3(a)), representing certain physical constraint information. For supporting relationships, the parent node needs to include a horizontal supporting surface to stably support the child node. For proximal relationships, the 3D geometries of adjacent nodes should not overlap. On the other hand, based on the similarity between the semantic and geometric information and considering the constraints between nodes, the nodes in Figure 3(a) are replaced with complete and interactive CAD models (including articulated CAD models), resulting in a virtual scene that can be used for robot simulation and interaction, as shown in Figure 3(b). This virtual scene preserves the functionality, i.e., the actionable information, of the real scene to the extent permitted by the perception capabilities and effectively enables simulation of interactions with objects in the real scene. Furthermore, the resulting scene graph representation includes a complete description of the environmental kinematics and constraint states. It can be used to predict the short-term quantitative effects of robot actions on kinematic states, assist in robot motion planning, estimate the long-term qualitative effects of robot actions on constraint relationships, and support robot task planning.
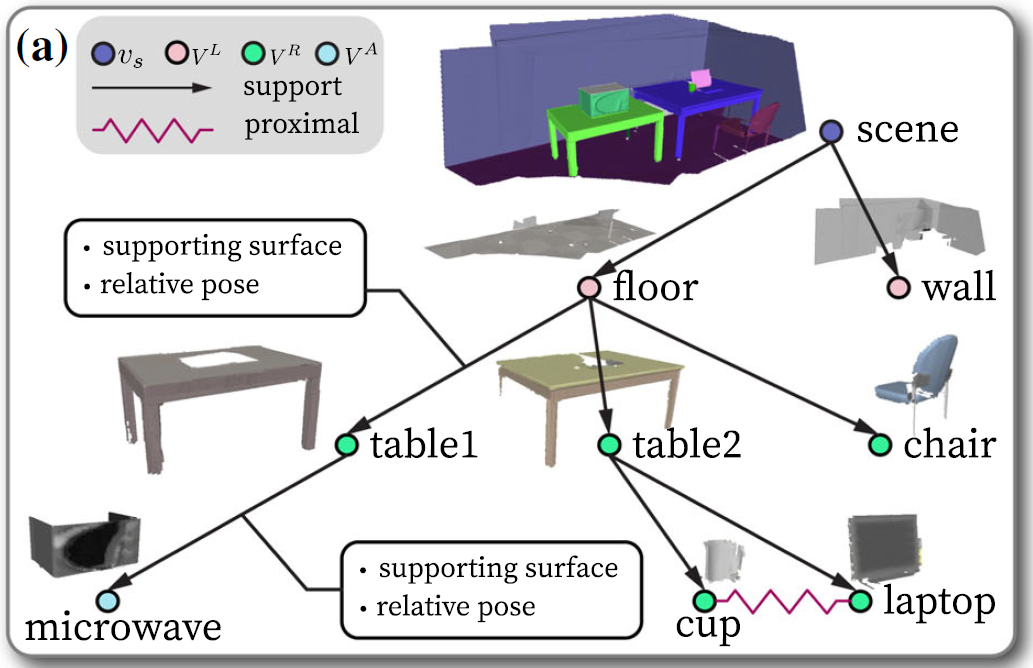
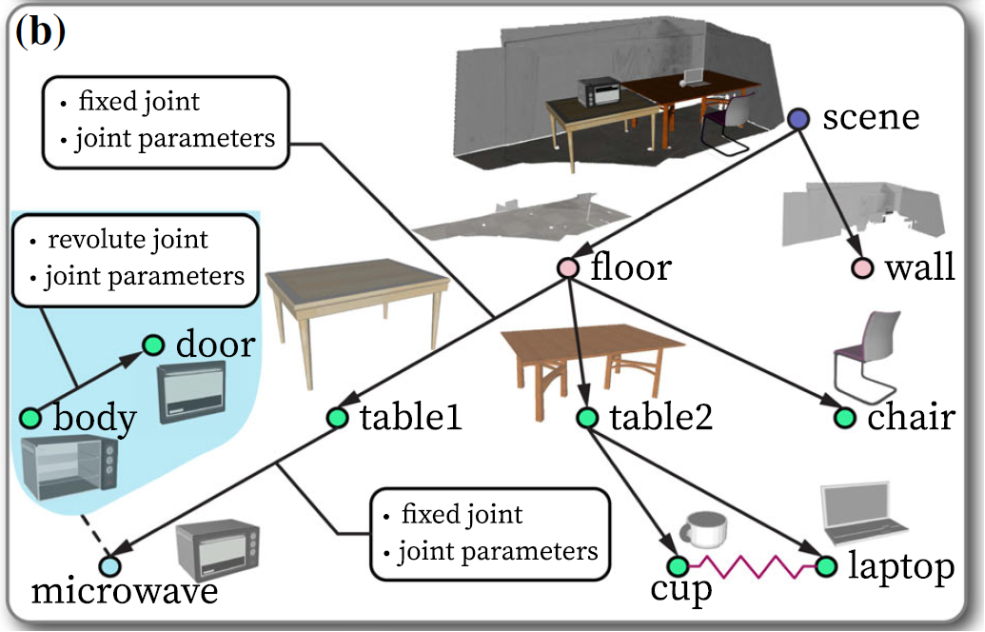
Fig. 3 (a) Directly reconstructed scene graph, (b) Interactive scene graph after CAD model replacement
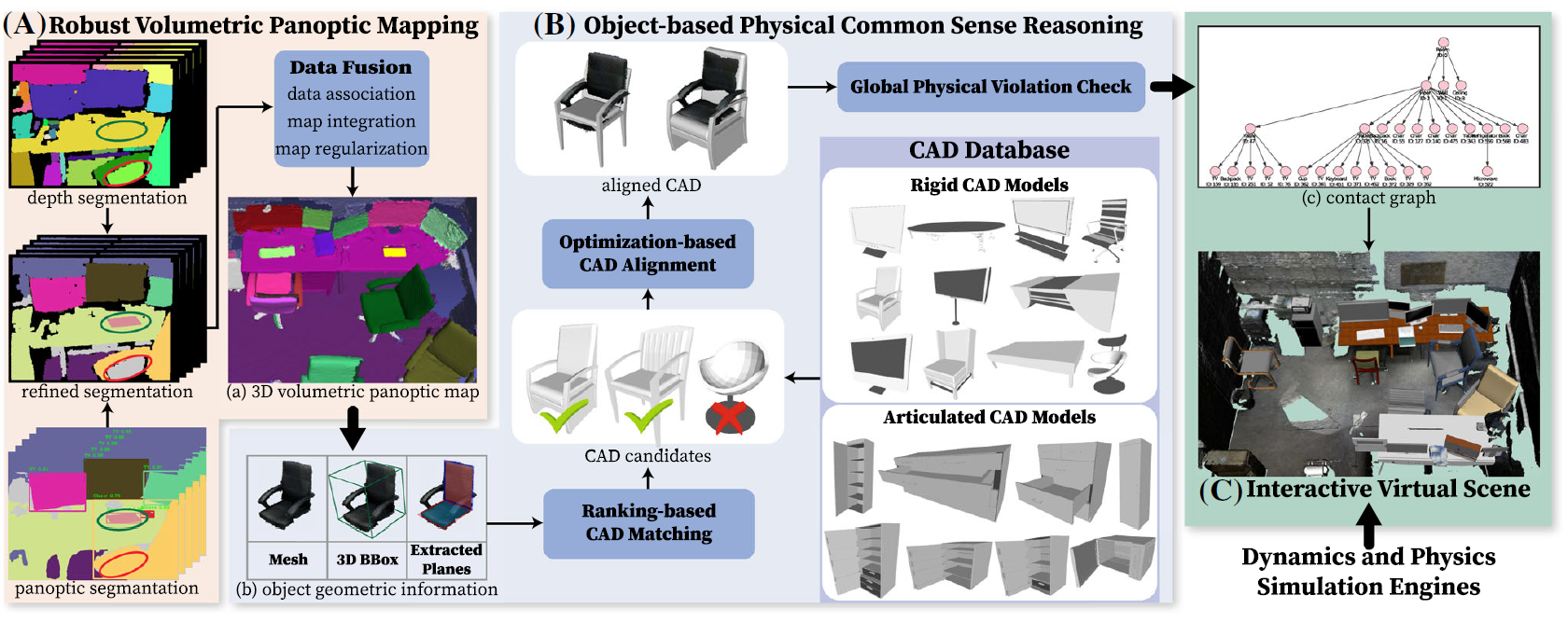
Fig. 4 Flowchart of the computer vision system used for the reconstruction task
To accomplish the aforementioned reconstruction task, the authors of the paper designed and implemented a multi-module computer vision system: a volumetric semantic panorama mapping module in Figure 4(A) and a CAD model replacement inference module based on physical knowledge and geometry in Figure 4(B). The former is used to robustly recognize, segment, and reconstruct the dense geometry of objects and room structures in complex real environments using RGB-D cameras. It also estimates the constraint relationships between them to obtain the scene graph as shown in Figure 3(a). The latter focuses on how to select the most suitable CAD models from a CAD model library based on the reconstructed object’s geometry and identified constraint relationships. It also estimates their poses and scales to achieve accurate alignment with the original objects, thereby generating the interactive scene graph shown in Figure 3(b). Figure 5 showcases the reconstruction results of a real office scene using the Kinect2 camera, including volumetric panoramic reconstruction [Figure 5(a)], common interactive virtual scenes in Figure 5(b), and examples of robot interaction after importing the virtual scene into a robot simulator in Figure 5(c). We can see that even in complex and heavily occluded real scenes, the proposed reconstruction system can effectively establish interactive virtual scenes. Figures 5(d-f) present some interesting examples from this experiment: In Figure 5(d), due to occlusion caused by a chair, the same table is reconstructed as two relatively small tables. Figure 5(e) shows a well-reconstructed workspace where all objects are replaced with CAD models that resemble their appearances. In Figure 5(f), the chair was not identified, resulting in a similar situation as in Figure 5(d) where it is occluded by the table. However, the refrigerator and microwave in the scene were reconstructed and replaced with articulated CAD models capable of complex interactions.

Fig. 5 Reconstruction results in a real-world environment using a Kinect2 camera

Fig. 6 Robot task and motion planning in the reconstructed virtual scene.
In the reconstructed interactive virtual scenes, aided by the motion chains and constraint information reflected in the scene graph, robots can engage in task and motion planning [3,4]. The simulation results are shown in Figure 6. In recent related work [5], based on the scene graph representation described earlier, robots can directly perform complex task planning using graph editing distance and efficiently generate actions.
This work presents a novel scene reconstruction problem and scene graph representation that provide essential information for robot autonomous planning and offer interactive virtual scenes with functionality similar to real-world scenes for simulation testing. Furthermore, a complete computer vision system has been developed to address the proposed scene reconstruction problem. The experiments demonstrate the effectiveness of the proposed scene reconstruction method and the potential of the scene graph representation in robot autonomous planning.
Looking ahead, we anticipate further advancements in this work, including achieving more robust and accurate matching between rigid and articulated CAD models and reconstructed geometry, integrating more complex potential action information into the scene graph, and leveraging scene priors for robot planning. Scene graph reconstruction empowers autonomous planning, bringing us closer to more intelligent robots in the near future.
References:
[1] Han, Muzhi, et al. “Scene Reconstruction with Functional Objects for Robot Autonomy.” 2022 International Journal of Computer Vision (IJCV), link.springer.com, 2022.
[2] Han, Muzhi, et al. “Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments.” 2021 IEEE International Conference on Robotics and Automation (ICRA), ieeexplore.ieee.org, 2021, pp. 12199–206.
[3] Jiao, Ziyuan, et al. “Consolidating Kinematic Models to Promote Coordinated Mobile Manipulations.” 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, doi:10.1109/iros51168.2021.9636351.
[4] Jiao, Ziyuan, et al. “Efficient Task Planning for Mobile Manipulation: A Virtual Kinematic Chain Perspective.” 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), ieeexplore.ieee.org, 2021, pp. 8288–94.
[5] Jiao, Ziyuan, et al. “Sequential Manipulation Planning on Scene Graph.” 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), ieeexplore.ieee.org, 2022.


